Platonic Research learn from your workflows, quantifies time wasted on repetitive work, and deploys AI agents that do the boring tasks for you. No APIs, no scripts, no integration needed.
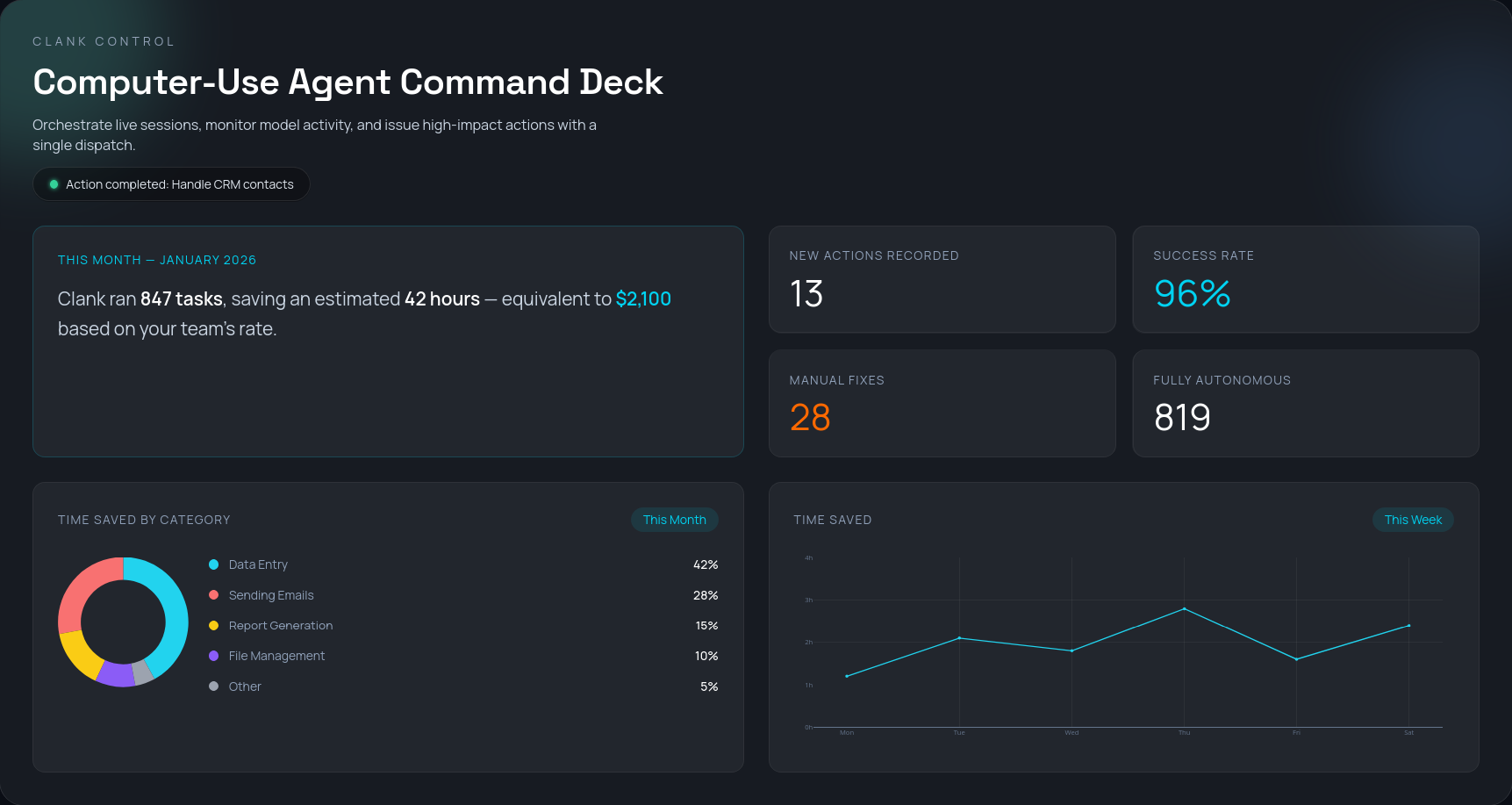
Traditional automation means months of work before you see results. We show results in days.
Before we can automate intelligently, we need to understand what's actually happening. We start by watching, then we act on what we've learned.
Observe workflows. Identify repetitive and automatable tasks. Quantify the time wasted.
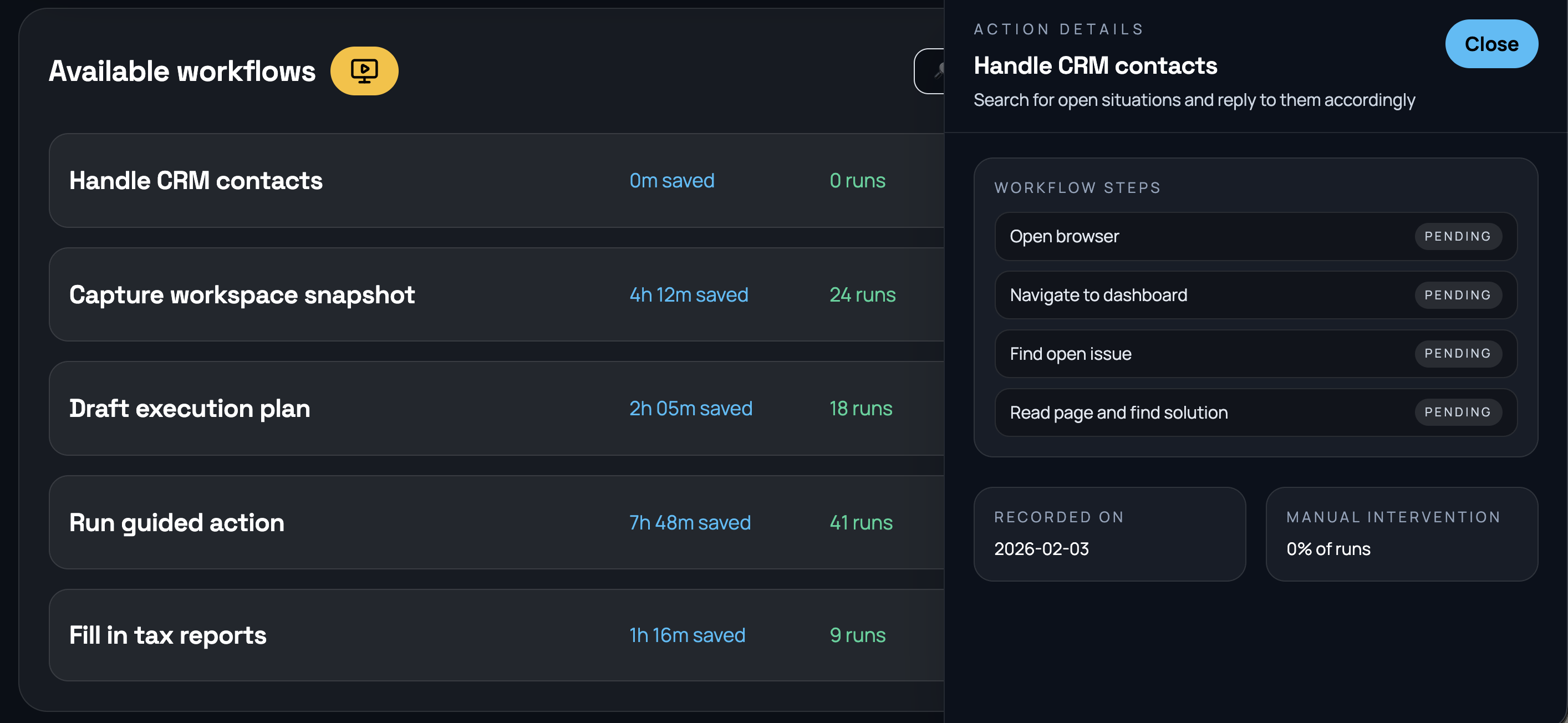
Train AI agents on observed workflows. Deploy with human control.
Out-of-the-box compatibility with any application.
Salesforce, SAP, NetSuite, Google Workspace. If it runs, we work with it. No integrations required.
Workers can pause observation anytime. We observe processes, not people.
Your data never leaves your infrastructure. Full flexibility for regulated industries.
Auditable workflows, no raw screen storage, enterprise security standards.
We've traded the comfort of academia for the chaos of startups. No regrets.






Tell us what's painful. We'll show you what's possible.
Write to info@platonicresearch.com and we'll route it to the right folks with a scoped next step.